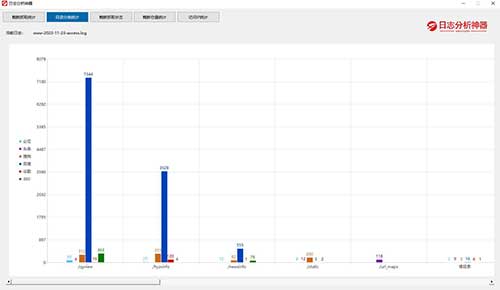
百度蜘蛛在抓取网页时,会有两套蜘蛛系统,最常见的是baiduspider/2.0(源码抓取),而如果你发现你的日志中出现很多baiduspider-render/2.0(渲染抓取),那就需要特别注意你的网站是否有js作弊情况,如有请尽快处理,避免被降权。
百度蜘蛛baiduspider-render/2.0和baiduspider/2.0具体有什么不同,首先,baiduspider-render/2.0主要用于抓取网页的渲染内容。它会模拟浏览器渲染网页的过程,获取网页中的图片、视频、样式等元素。这样可以确保搜索结果中显示的内容与用户实际看到的一致。而baiduspider/2.0则主要用于抓取网页的源代码,它会直接获取网页中的HTML、CSS、JavaScript等内容。其次,baiduspider-render/2.0和baiduspider/2.0在爬取策略上也有所不同。由于baiduspider-render/2.0需要模拟浏览器渲染过程,因此它的爬取速度相对较慢。而baiduspider/2.0则可以直接获取网页源代码,因此它的爬取速度相对较快。
此外,baiduspider-render/2.0和baiduspider/2.0在处理动态内容时也有所不同。由于baiduspider-render/2.0会模拟浏览器渲染过程,因此它可以正确处理网页中的JavaScript动态内容。而baiduspider/2.0则只能获取静态的HTML内容,对于JavaScript动态内容则需要通过其他技术进行处理。
接下来,我们再以百度蜘蛛实际抓取情况做以对比,看看baiduspider/2.0抓取的页面类型,及baiduspider-render/2.0又是抓取的什么页面类型
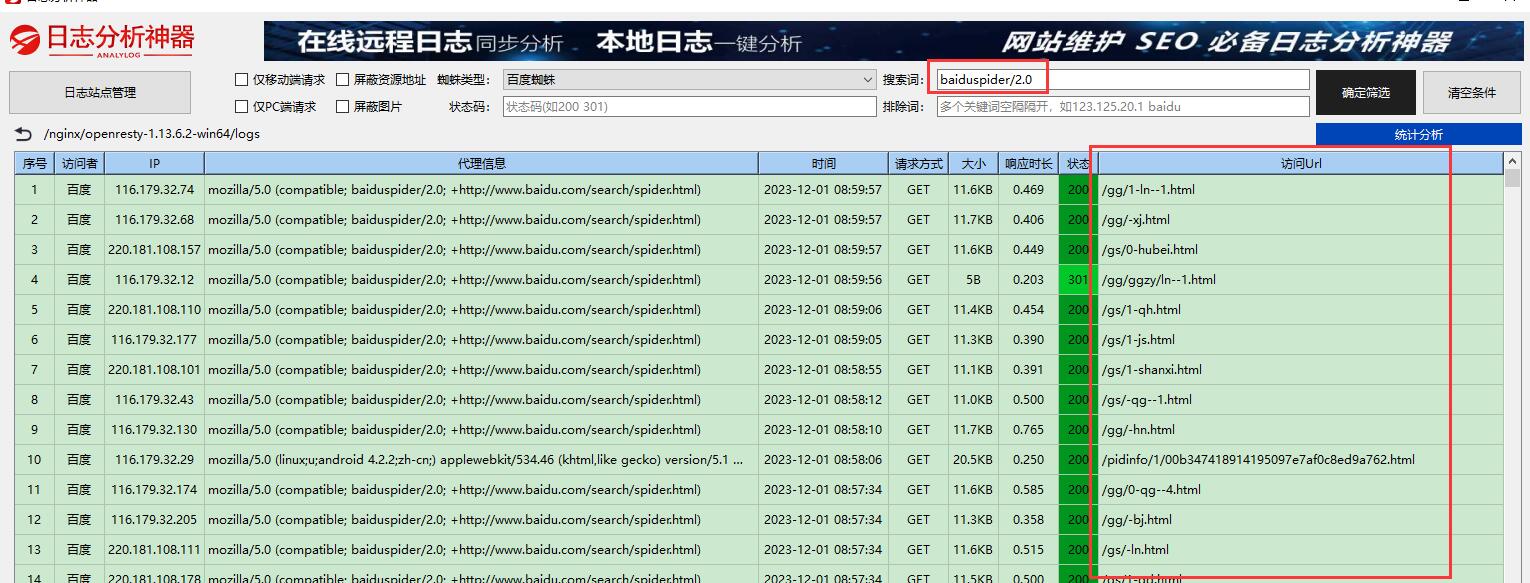
baiduspider/2.0
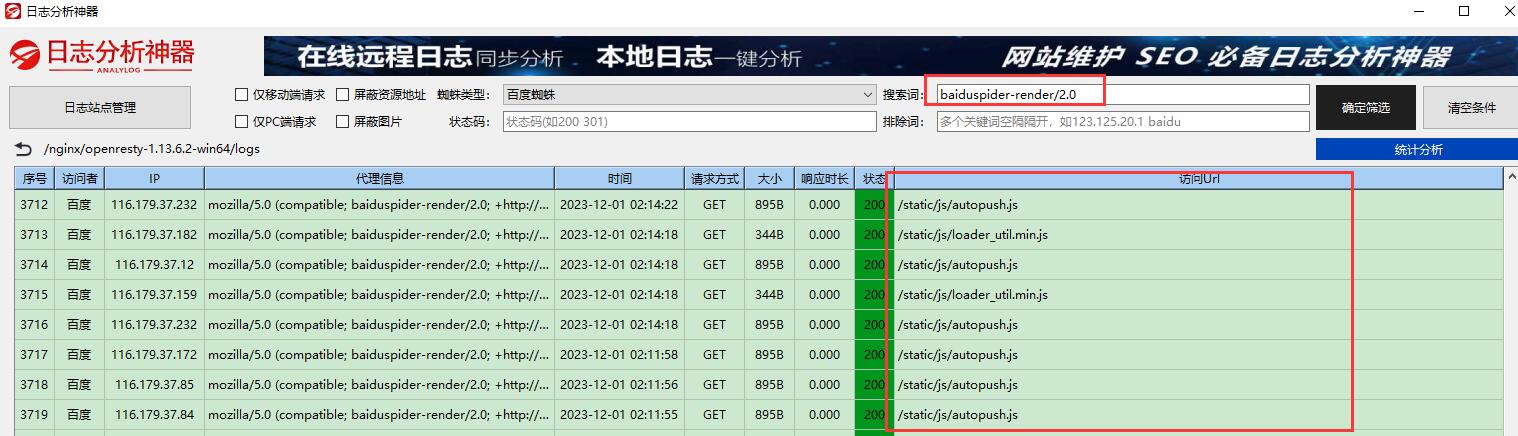
baiduspider-render/2.0
从以上案例了感觉baiduspider-render/2.0更多抓取的是js文档,但再看看下面这个截图,baiduspider/2.0与baiduspider-render/2.0也会抓取同样的页面!
